Hi,大家好。有关于的Foxtrot的中文资料实在是太少了,和官方support联系还是很麻烦(联系ing)。所以又来这里讨教了!
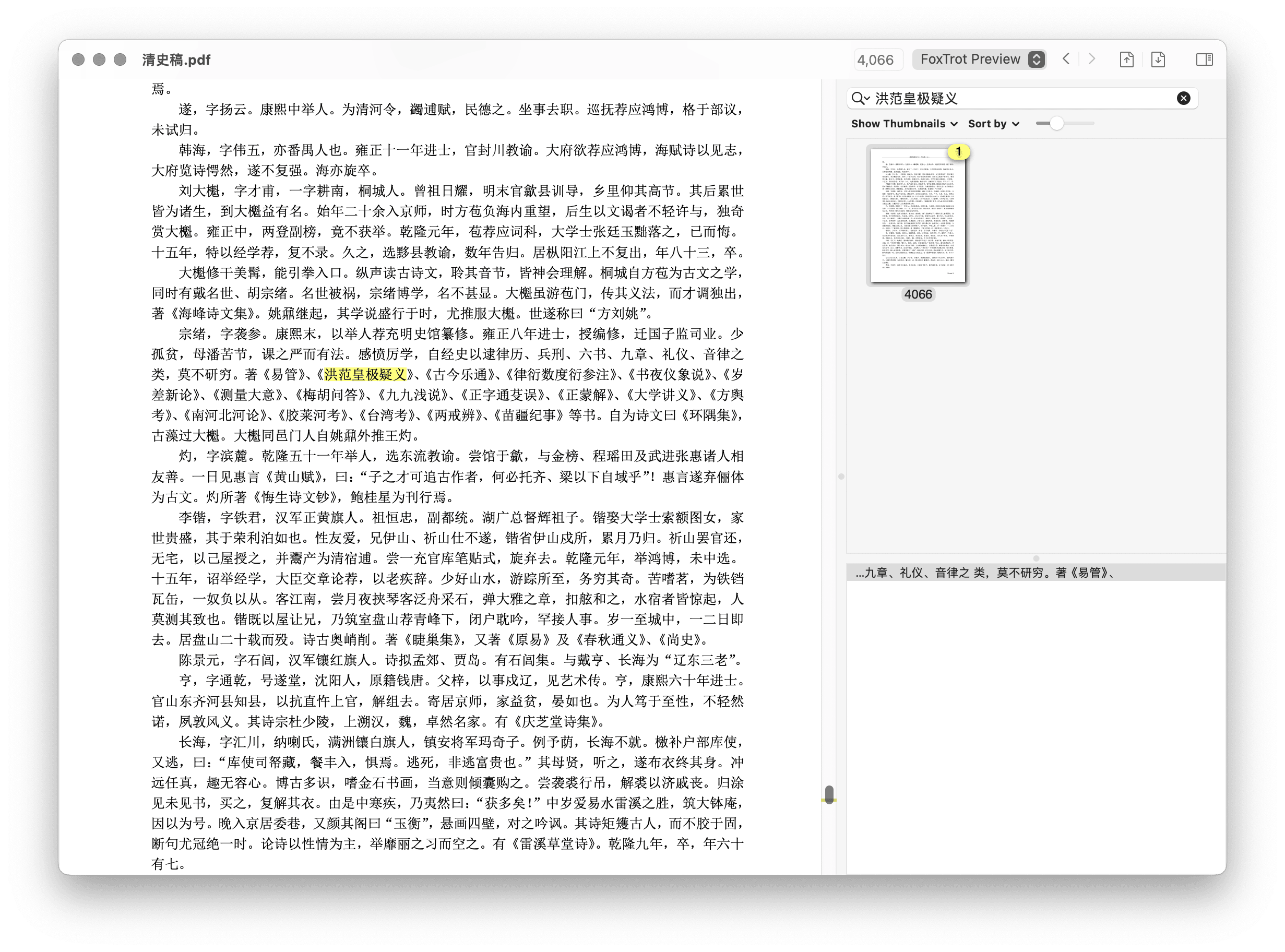
我有一本文字版的《清史稿》,4453页。目前我已经索引完成,正打算使用搜索。现在,我需要在其中搜索一本书的名字:《洪范皇极疑义》。只要输入“洪范皇极疑义”,在preview和devonthink中可以直接定位到具体书的具体位置,在devonthink中,打开enable Operator & Wildcards可以搜索到,否则搜索不到具体页码。但是在foxtrot中则什么都搜索不到。
我已经试验了如下动作:
-
我搜索的正文中包含“洪范皇极疑义”这样一段连续的字符,用preview查看可以完整复制下来这六个字。
-
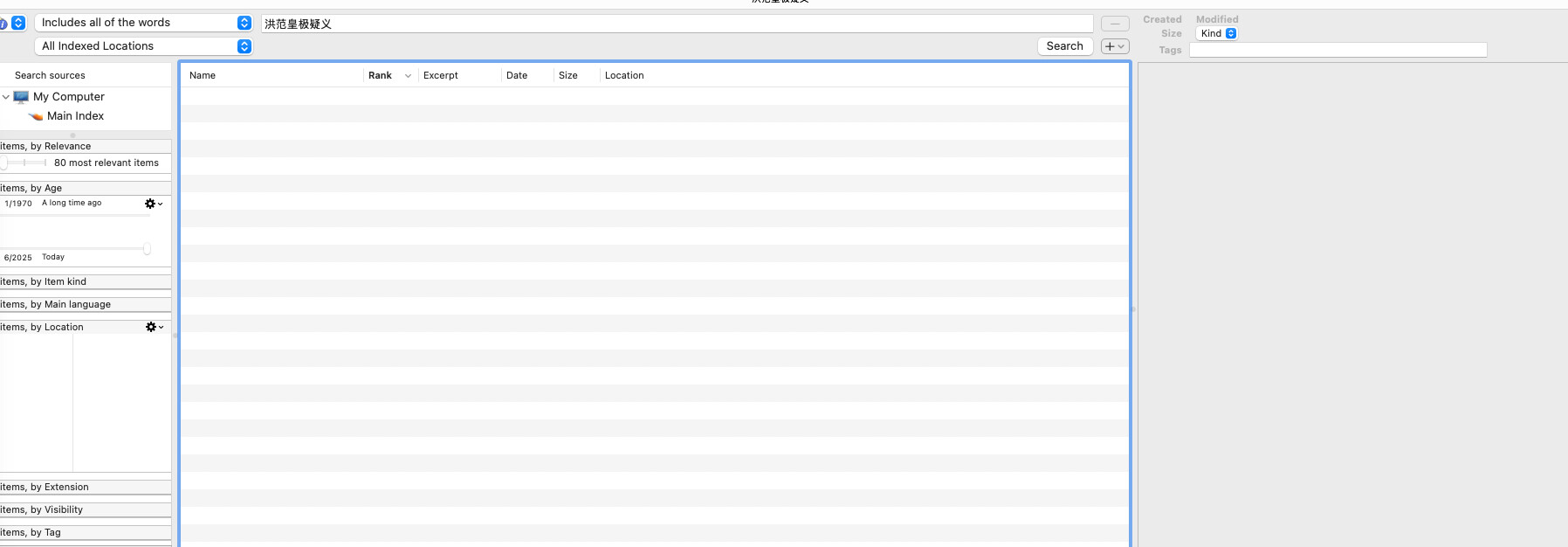
输入不包括直引号的各种词语:“洪范皇极疑义”,无法搜索到;我尝试了“洪范”, “疑义”, or “皇极”以及他们的组合,单独输入“洪范”,“皇极”与“疑义”时均可以搜索到“清史稿”PDF文件,但使用“洪范皇极”或者“皇极疑义”时则无法搜索到。
-
输入用直引号包括的各种词语:“洪范”, “皇极”or“疑义”, ,在使用“includes all of the word”模式时,三者独立或混合地输入后都可以搜索到指定的“清史稿”PDF文件;当我使用“includes neighboring words”模式时,我必须把around one line数量限制在10words及以上才可以用(“洪范” “皇极”)搜索到该文件,如果使用三者,我需要设置到10000words,如果使用(“皇极” “疑义”),我需要设置为1000words。
-
我将原文件删除,此时,Foxtrot只显示索引结果。此时,无论搜索哪一个关键词,都无法找到该本书并定位到我想要找的位置。同时,我查看到plain text文件,这本书有4453页,在索引中最远只有3998页。
有没有什么办法可以做到,在foxtrot中像dt和preview那样搜索呢?因为foxfrot的搜索速度超级快,相较于dt需要等十几秒,转圈圈,优势还是巨大的。
文件:清史稿.pdf - Google 雲端硬碟
更新:
- 开发商确认似乎是文件字符数太多的原因,导致索引只处理了4500多页中3998页,大约500多万字,因为没有索引,所以关键字找不到。我拆分成两个较小的pdf就可以搜索了。
- Foxtrot默认使用的spotlights phaser似乎是有上限(开发商尚未确定)。
- 替代的phaser:Xpdf似乎对中文有较大的局限性,对这个文件索引出来的全部是乱码。
- 如果确实遇到类似问题,较为安全的做法是以foxtrot索引中的最大文字量为界限拆分文档,这份文档中,Foxtrot共计索引了5244425字。