交互式文件命名,根本的目的是方便檢索、用3~4個區塊產生的交集,把文檔搜索範圍縮減到最小。
如果在命名浪費太多時間,這會本末倒置,但要是沒有命名的紀律,後續浪費的時間比前面本末倒置的還更多。
如果參雜其他目的,例如:我希望日後能根據標題和文檔本身,在一定時限內(一年?)在網路上找回原出處。
所以在標題已經很克制地補充了文檔來源發文者帳號或暱稱,以及發文日期,又是2個區塊了。
照做的話,還真的能實現目的,代價就是繁瑣的步驟、積少成多的時間。
我被迫思考囤積的問題,除非上述步驟都有辦法自動地、且準確地做到。
說來感傷,直到去年八月為止,有一款twitter的瀏覽器插件,
它可以自動擷取用戶在twitter的發文、轉發、Like、Bookmark的內容,
而且文檔名稱是嚴格有條理的,帳戶名稱、發文的流水號(網址的一部份)、發文時間、我的轉發時間、圖片號碼。
我不認為這種收集行為是無效的囤積,
因為這些圖不是社群平台的推薦,那是我已經有意無意,
經由我的意志和審美主動蒐藏的內容,
它的集合絕對是社群平台推薦的子集合,且和我可能喜歡的內容至少9成重疊。
哪天自動推薦的內容索然無味,我隨時可以瀏覽我確認過的內容。
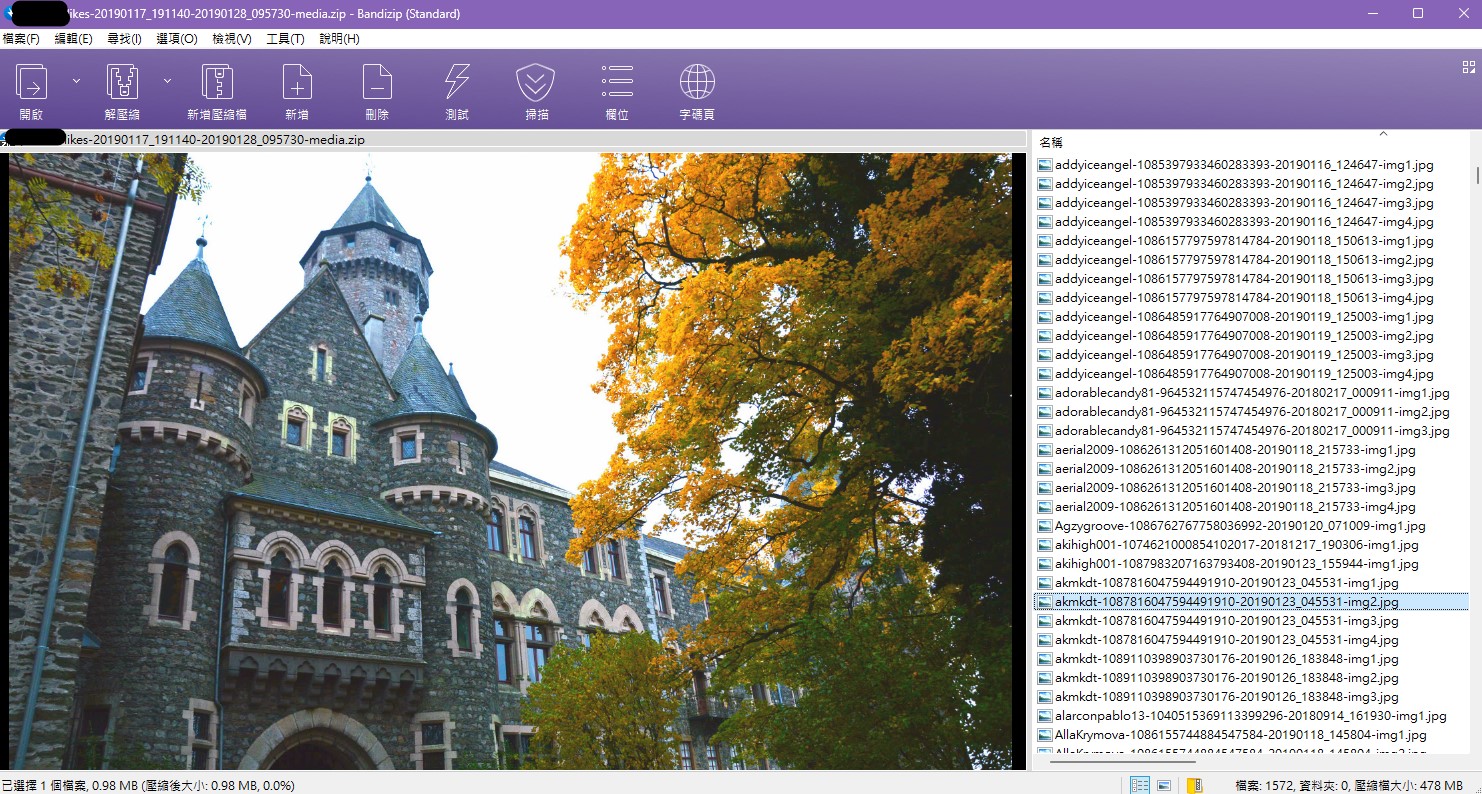
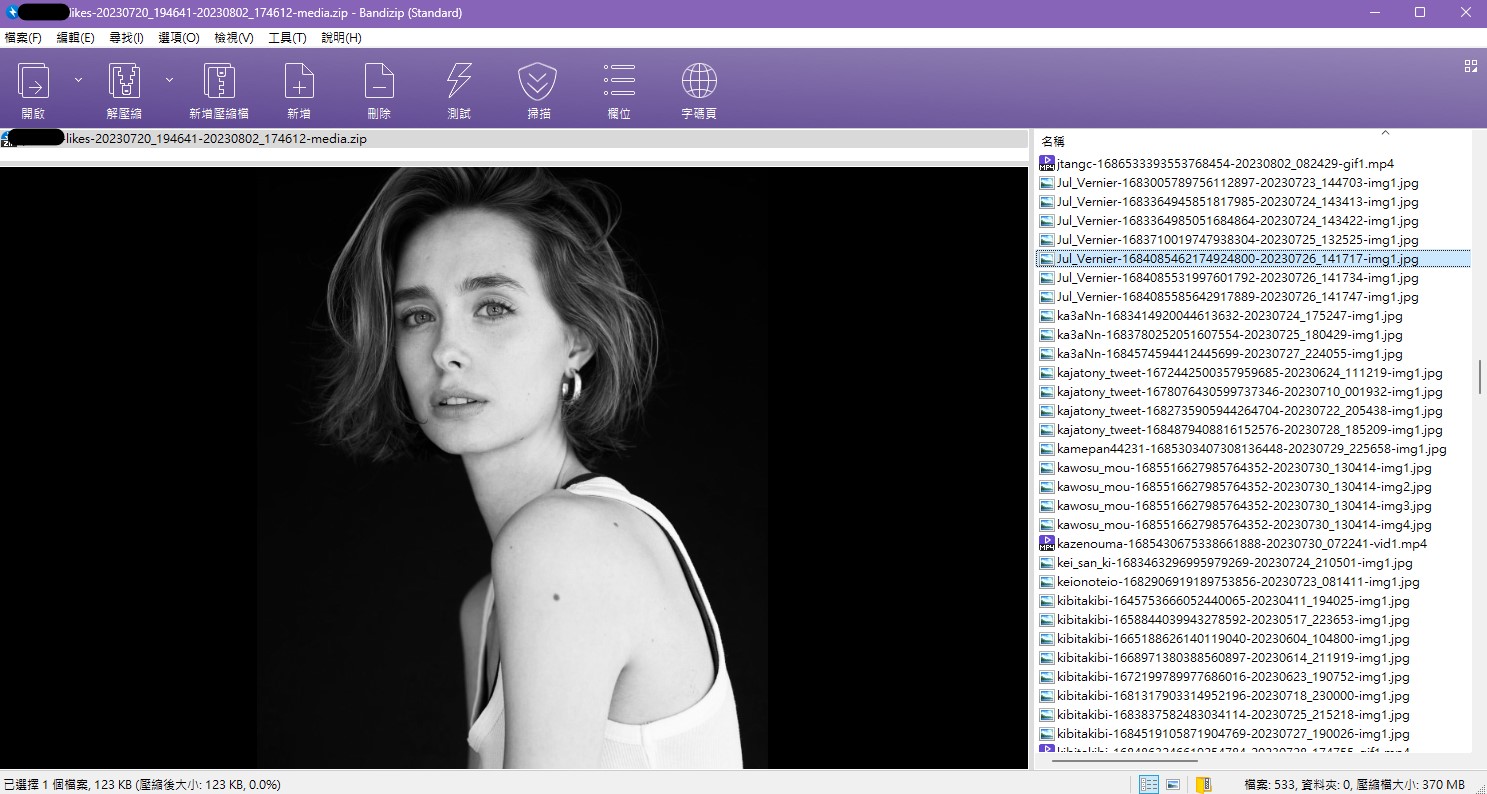
由於去年中twitter改變API的規則,該插件無法繼續工作,
時候到了就此失效。
我利用此工具自動擷取這麼多文檔,但這些收藏充其量只算半成品。
因為它有條理,我深信很久很久以後總有辦法對其進一步地整理和分類。
它們至少比命名紊亂的內容、比起書籤垃圾場(數量級遠少於此收藏)有可讀性。
就是這堆半成品,我只是完全隨意亂點,都能找到我滿意的內容,
明明只是個附帶有預覽圖片空能地解壓縮工具,本身介面中上,
搭配擷取過的、篩選過的內容,此時我的體驗比在好多地方還舒適愜意。
到此插件徹底失效之前擷取的內容,我在硬碟裡一直保留兩份位置給它們。